
ISSTA 2026|LAVE:面向扩散语言模型的约束解码
ISSTA 2026|LAVE:面向扩散语言模型的约束解码推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
来自主题: AI技术研报
9051 点击 2026-07-16 10:09
 搜索
搜索
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
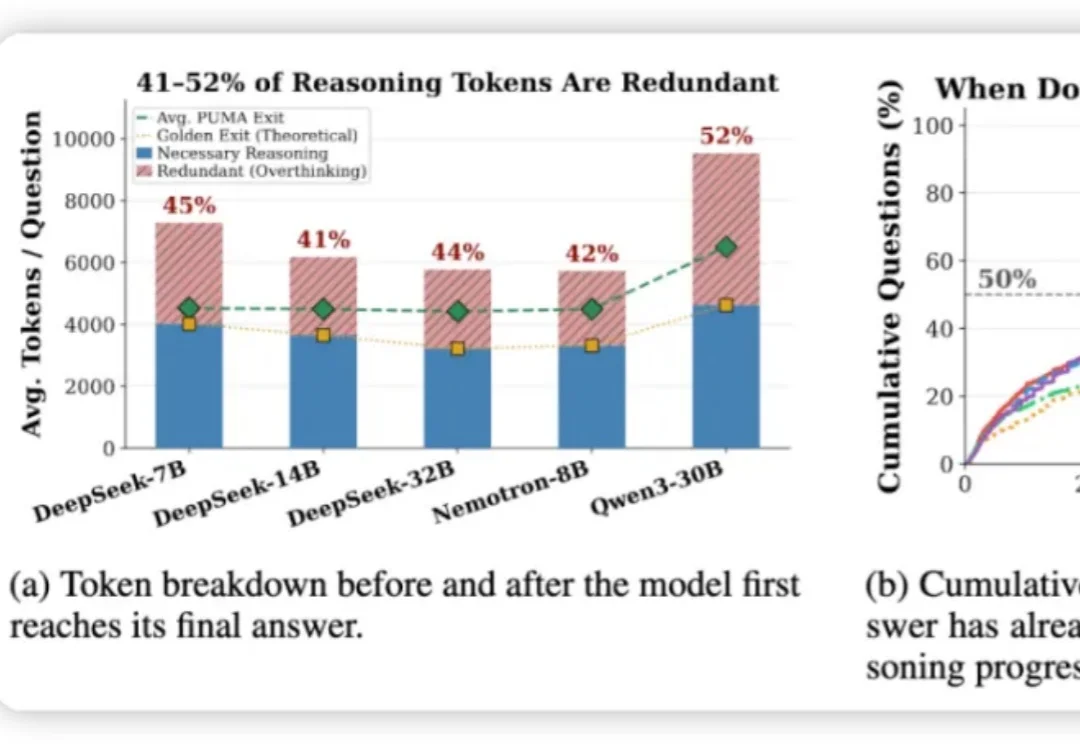
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

刚刚,DeepSeek V4 进行了一次更新。新推出了投机解码(Speculative Decoding)框架 DSpark,并同步开源了支撑该版本的全栈推测性解码框架 DeepSpec。DeepSeek-V4-Pro-DSpark 并非全新架构模型,而是在 DeepSeek-V4-Pro 基础上引入了推测性解码模块。此次更新的重点在于工程落地,而非模型能力本身的迭代。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

由智源研究院牵头研发的众智 FlagOS 第一时间对两个“巨无霸”模型进行全量适配,已经完成 DeepSeek-V4-Flash 在8款以上 AI 芯片上的全量适配与推理部署,包括海光、沐曦、华为昇腾、摩尔线程(FP8)、昆仑芯、平头哥真武、天数、英伟达(FP8)等芯片。FlagOS 同时正在推进 DeepSeek-V4-Pro 模型在多个芯片的迁移适配,晚些时间开源出来,敬请期待。

今天,我们全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源。DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本:
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。